为了实现重要商业应用的零误工,一些企业把数据中心也联合起来,这样一来当某个数据中心出现故障时,上面的应用可以切换到另外一个数据中心。服务器虚拟化技术的出现,如VM迁移,使这一选择更具灵活性。有些企业更胜一筹,通过创建相互连接的数据中心同时在两个不同的数据中心里运行相同的应用。
虽然有许多关于此部署的架构决策,但或许最关键的是两个数据中心如何通过DCI连接。应用与虚拟化软件的要保持同步,则需要两个数据中心之间的延时非常短,通常要控制在毫秒范围。这一要求在IT和数据中心设计师创建DCI架构性时起到了举足轻重的作用。
由DCI连接的应用需要使用以太网,这样就会带来巨大的挑战,包括延时问题,还可能创建环路从而导致网络崩溃。有多种方案可以应对这种挑战,包括使用运营商服务,如Virtual Private LAN服务,但是这些方案也存在自身局限性。
例如,当VPLS 可用来阻止运营商网络中的循环时,它不会阻止客户内部网络中出现循环。VPLS可能带来延时并因此影响应用的使用。客户或许想使用Multichassis Link Aggregation之类的技巧,在这种技巧中,两到多个以太网交换机在本地合并到一起使两条以太网连接成为一条。
其他选择还包括使用暗光纤和DWDM,二者都可以提供很快的连接。虽然暗光纤和DWDM都很贵,但是它们能为DCI提供最优连接。
数据中心互联增强应用有效性
应用如果出现故障,对企业的损失是比较大的,特别那些关乎关键业务的系统。阻止应用故障的策略之一就是创建数据中心的互联,或是用DCI连接两个数据中心,这样当故障出现在一个数据中心的时候,应用会继续在另一个数据中心里运行。在ITIL推荐要发挥所有固有资产价值以及使用积极数据中心模式的倡导下,这种方法得到了进一步发展。
有两种方法可在两个数据中心中创建可用性较高的应用。第一是选择一个应用,在其中一个数据中心中使用这个应用,而另外一个数据中心则作为备用。这样,当第一个数据中心出现故障时,应用会转换到另一个数据中心继续运作。监控管理技术,如VMmare的vMotion,可以让虚拟机从一个物理服务器转移到另一个服务器上,通过此项操作来实现进程的持续运作。
第二种选择是应用同步化,这样就可以在两个数据中心里同时运行应用。群集,共享和存储复制等技术都有助于实现同步化。
但是许多有应用运行的群集和复制技术都需要共享一个以太网,而且以太网数据会通过单点播放/多点播放或广播的形式发送给集群中的所有要素(服务器,数据库和存储)。
问题在于,虽然以太网可在数据中心电缆上传输几百米,但是它的局限性也会对企业创建DCI形成阻碍。这些阻碍包括延时和带宽挑战。
运营商也提供了一些服务期望能应对诸如此类的挑战,但是这些服务在部署方面仍然存在局限性,而且还不足以保障应用的高可用性。我们将审查这些挑战并介绍一些可创建DCI连接的替代物。最佳选择是使用Multichassis Link Aggregation (MLAG)等技术,因为它们使用了暗光纤和DWDM服务。
延时问题
延时是一个比较麻烦的问题。造成延时的原因主要有三个,最主要的就是距离。距离越远,电子信号的传输时间就越长。
两个数据中心之间最常见的延时底线由VM迁移来决定,如用于VMware vSphere服务器的vMotion,它可以让虚拟机从一个物理机组迁移到另一个机组。VMware称,源服务器和目标服务器之间的延时必须小于5毫秒 (vMotion Metro 许可证更改了vMotion TCP堆栈使其支持动态套接缓冲,这样便调整了TCP协议堆栈中里的内存数据包缓冲,按照延时/带宽情况优化性能,可以容许稍长一点的延时)。
你的企业有没有为改善网络制定预算?
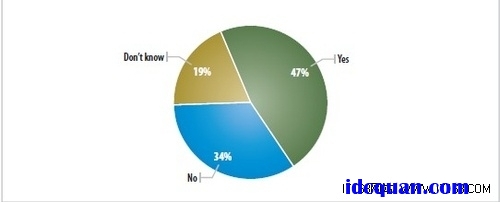
▲图一:改善网络连接的预算
实践结果是数据中心的距离在50-75 公里范围内可以进行可靠的VM迁移。
遗憾的是,这个距离对于较严重的灾难恢复计划而言还不够(如飓风,地震或是区域性的电信故障)。因此企业要平衡应用应对灾难恢复要求的弹性。
延时还会影响存储复制,特别是在同步复制中,数据块写入必须在两个站点间在5-10毫秒内复制完,这要取决于恢复点的目标恢复时间。
对于同步操作而言,延时的影响比较小,因为写入确认可以在不影响存储源的情况下被接收到,而且请求/响应顺序没有通过写入确认来限制。但是如果你计划进行亚秒故障转移,通常需要进行同步存储来确保数据不被丢失。
另一个导致延时的不显著因素是运营商往往使用隧道协议,如MPLS,ATM或SONET.MPLS网络的问题在于运营商不能保障网络中两站点之间的路径。运营商网络可能在一个城市的多个节点跳动,这样以太网络帧在转发时会增加处理延时。
最后一个导致延时的要素是带宽。网速快当然延时就短;例如,1G接口的延时为5.7毫秒,但是10G接口的延时仅为0.57毫秒。简而言之,改善延时问题的简单方法就是使用高带宽网络。
QoS挑战
应用在两个数据中心之间的有效性也会影响QoS设置的限制。以太网有五个可用的QoS类可以对数据流进行分类管理,这样便能限制第二层数据中心互联可以处理的服务量。
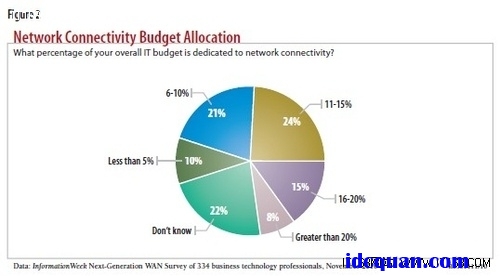
同时,在DCI上你还有两股不同类型的数据来维持应用的有效性:突发性,高带宽应用和低延时,持续爆发的监控迁移数据流。因此,你必须设计好QoS设置使其满足两种数据的需求。
注意,不论有多少带宽可用,都可能出现瞬时数据爆发占用所有带宽,从而使你的QoS设置失效。这种情况可能出现在数据路径的任何一处,即便是以微秒来计算的数据爆发都严重影响整体传输性能。网络阻滞可能导致各种数据回流,致使问题复杂化。
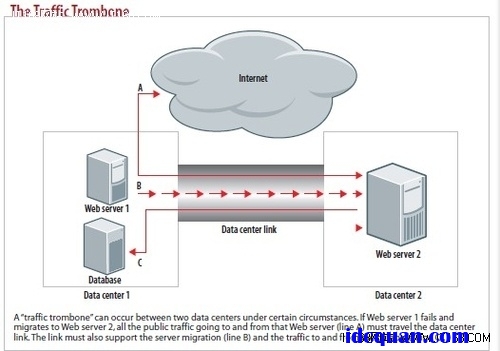
Traffic Trombone
创建DCI过程中以太网面临的另一种挑战是“Traffic Trombone(网络内部的信息往返流动)”(图3)。以在线商务为例: 它有面向公众的Web/应用服务器,该服务器可连接至内部数据库服务器。假设,有一个VLAN已被扩展到第二个数据中心。
如果该Web服务器在两个数据中心间徘徊,它会保留相同的IP地址,所有数据都必须穿过DCI链接。如图3所示,里面包括了出入外部用户端的数据以及出入数据库的数据。
另需增加的带宽严重限制了该方案的可扩展性而且还增加了带宽的成本。供应商正推出DNS负载平衡之类的传输系统,因为这样的系统可以随时将数据流发送到新地址,不过它们的实用性还不足。例如,如果你的数据库没有用类似Web服务器这样的监管平台进行虚拟化,你如何能对推动数据库服务器及其相关应用和Web服务器机制进行管理呢?
阻止循环
以太网为DCI的创建带来了另一个技术性障碍。以太网创建于30年前,是一种本地网络协议,所以当时没有考虑到跨机器扩展。就设计而言,以太网是一种多路存取技术,所以可通过网络上的所有端点接收以太网广播和多点传播帧。
因此,当主机发送以太网广播或多点播帧时,这个帧必须通过所有以太网进行转发,包括DCI.当广播帧循环回到以太网网络时,它就会被所有交换机转发,即便它此前已被广播。这就制造了一种快速消耗所有网络带宽的条件,而结果便是导致网络瘫痪。
数年前开发的生成树协议就是为了阻止这种循环,而且它现在仍在沿用,尽管Rapid Spanning Tree Protocol (RSTP)已经在可靠性和速度方面有所超越。
问题是Spanning Tree不能在长距离传输中效果不好。当网络延时超过250毫秒时,RSTP就不再能阻止循环。
结论便是Spanning Tree不能在创建DCI时有效阻止循环。试一下你就会发现它易受单向数据流的影响,而其他操作都会出现故障。虽然存在单向链路检测协议(UDLD)这样的补丁,但是运营商的服务很有可能会拦截UDLD或是其他减少STP限制的功能。
供应商开发出了很多技术复杂的方案用于解决循环问题。三种最常见的方案就是VPLS,MLAG/PortChannel和OTV.